Chapter 1
DBMS
- Relational Database Management System
- Use table link to each other (Customers, Orders, Products)
- SQL是我们用于这些关系数据库的语言
- RDBMS:MySQL, SQL Server, Oracle
- NoSQL
- 他们有自己的查询语言,不懂SQL
SQL是结构性数据。
什么是非结构性数据?
非结构性数据(Unstructured Data)是指那些没有明确结构或预定义格式的数据,通常不易存储在传统的关系型数据库中。 与结构化数据(如表格、数据库中的行列数据)不同,非结构性数据没有固定的格式或组织方式,需要特殊的技术来处理和分析。
特点:
- 缺乏固定结构:数据没有统一的模式或关系(如行列形式)。
- 多样性:它可能包括文本、图像、视频、音频等多种类型的内容。
- 难以存储和分析:需要使用不同的存储解决方案(如NoSQL数据库、分布式存储系统)和数据处理技术(如自然语言处理、计算机视觉等)来提取有用信息。
常见类型:
- 文本数据:如电子邮件、社交媒体帖子、博客、新闻文章等。
- 多媒体数据:包括图片、音频和视频文件。
- 传感器数据:例如来自物联网设备的实时数据流,往往不按固定格式存储。
- 网页内容:网站上的内容通常是HTML格式,但其内部信息的组织结构很松散,无法直接应用关系型数据库模型。
Chapter 2
2.1 The SELECT statement
USE sql_store;
SELECT * -- which column
FROM customers
-- WHERE customer_id = 1
ORDER BY first_name
2.1 The SELECT Clause
SELECT
first_name,
last_name,
points,
(points + 10) + 100 AS "discount factor"
FROM customers
AS可以重新命名(alias) Columns,如果新名称有空格,需要加上引号。如果没有空格,则不用加。
使用DISTINCT命令。
SELECT DISTINCT state
FROM customers
PRACTICE
USE sql_store;
SELECT name, unit_price, unit_price * 1.1 AS "new price"
FROM products
2.5 The IN Operator
SELECT *
FROM Customers
WHERE state IN ('VA', 'FL', 'GA')
-- WHERE state NOT IN ('VA', 'FL', 'GA')
如果想要简写OR XX OR XX OR XX,可以用IN + tuple
2.6 The BETWEEN Operator
SELECT *
FROM customers
WHERE points BETWEEN 1000 AND 3000 -- easier way
可以对 ≥ and ≤ 简写
2.7 The LIKE Operator 模糊搜索
We only want to get the customers whose name start with ‘B’.
USE sql_store;
SELECT *
FROM customers
WHERE last_name LIKE 'b%' -- start with b
WHERE last_name LIKE '%b%' -- b in whatever place
WHERE last_name LIKE '%y' -- ends with y
WHERE last_name LIKE '_y' -- ends with two characters and the last one is y
WHERE last_name LIKE '_____y' -- ends with six characters and the last one is y
use % means any types of characters, doesn’t matter it is uppercase or lowercase b
Practice
- Get the customers whose
- address contain TRAIL or AVENUE
- phone numbers end with 9
SELECT *
FROM customers
WHERE (address LIKE '%TRAIL%' or
address LIKE '%AVENUE%') AND
phone LIKE '%9'
2.8 The REGEXP Operator
为了防止记混淆,建议固定用一个方式。
Allow us to search more complex patterns
USE sql_store;
SELECT *
FROM customers
-- WHERE last_name LIKE '%field%'
WHERE last_name REGEXP 'field'
WHERE last_name REGEXP '^field$'
WHERE last_name REGEXP 'field|mac|rose'
WHERE last_name REGEXP 'field$|mac|rose'
^ beginning of the string
$ end of the string
| means OR
[] means single characters
[-] means range
2.10 The ORDER BY Clause
USE sql_store;
SELECT *
FROM customers
ORDER BY state DESC, first_name DESC
My SQL 可以在不同的排序选择里,选择非排序的列。也可以用于Aligns的排序
USE sql_store;
SELECT first_name, last_name, 10+1 AS points
FROM customers
ORDER BY points, first_name
-- better avoid
USE sql_store;
SELECT first_name, last_name, 10+1 AS points
FROM customers
ORDER BY 1,2 -- the order of the columns in SELECT
-- better avoid
AS 前面是内容,AS 后面是column的名称
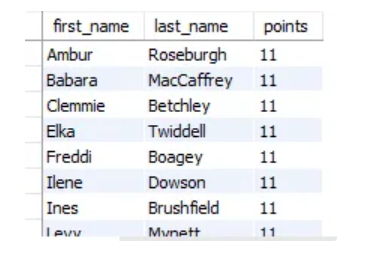
USE sql_store;
SELECT order_id, product_id, quantity, unit_price -- *
FROM order_items
WHERE order_id = 2
ORDER BY quantity * unit_price DESC
order by的内容可以是乘法
2.11 The LIMIT Clause
LIMIT 限制选择的行数
分页,offset, 3 customers in one page
USE sql_store;
SELECT *
FROM customers
LIMIT 6,3 -- 6 means offset (jump 6 records), pick 3 records
-- page 1: 1-3
-- page 2: 4-6
-- page 3: 7-9
-- pick the 3rd page
LIMIT 6, 3 的含义是:跳过前6行,从第7行开始返回3行数据(注意:LIMIT 的索引从 0 开始,所以 6 表示第7行)。 此处是一页两组数据不是因为查询语句的关系。
Chapter 3
Joining Across Databases 跨数据库连接
USE sql_store;
SELECT *
FROM order_items oi
JOIN sql_inventory.products p
ON oi.product_id = p.product_id
看USE的是哪个库。没使用的库的table要加前缀。
Self Joins 自连接
自连接:我们将这个表和自己join一下,这样就可以选择每个员工和他们的管理人员的名字。
CREATE TABLE employees (
employee_id INT,
name VARCHAR(100),
manager_id INT
);
INSERT INTO employees (employee_id, first_name, manager_id) VALUES
(1, 'Alice', NULL),
(2, 'Bob', 1),
(3, 'Charlie', 1),
(4, 'David', 2),
(5, 'Eve', 2);
示例1:查询每个员工及其上级的名字
--
SELECT e1.name AS employee_name, e2.name AS manager_name
FROM employees e1
LEFT JOIN employees e2 ON e1.manager_id = e2.employee_id;
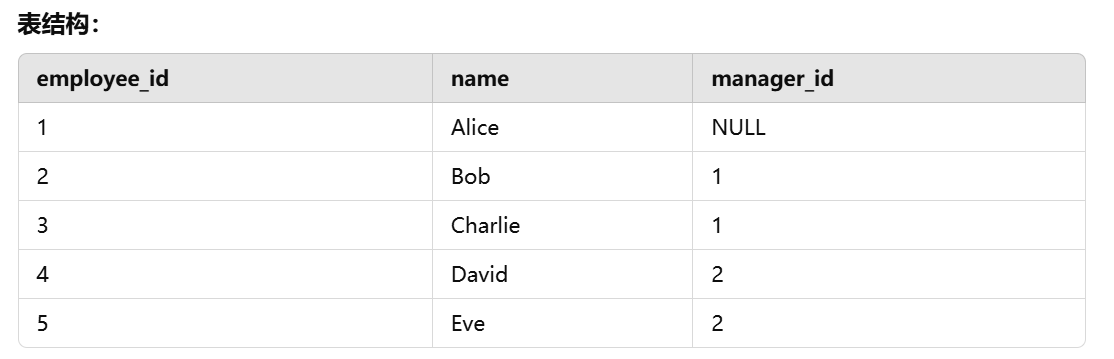
示例2:查询每个经理及其下属的数量
假设我们有一个员工表 employees,表中每个员工都有一个 manager_id 字段,表示他们的上级(即该员工的经理)。我们希望知道每个经理下属的数量。
表结构:
SELECT e1.name AS manager_name, COUNT(e2.employee_id) AS num_subordinates
FROM employees e1
LEFT JOIN employees e2 ON e1.employee_id = e2.manager_id
GROUP BY e1.employee_id;
COUNT(e2.manager_id) 会忽略掉 没有下属的经理(例如 Alice 和 Bob),因为他们的 manager_id 为 NULL,无法统计到他们的下属。
我们依然可以用groupby manager_id的方式来计算每个manager_id出现的次数,都是用来计算“每个经历的下属数量”。
为什么用自连接?
通过自连接,你不仅可以获得每个经理的下属人数,还可以获得其他更多的信息。例如,你可能想知道每个经理和每个员工的具体名字、或者经理的更多详细信息等。
自连接常见应用场景
- 员工和上级关系:查询员工及其上级的名称。
- 树形结构数据:处理具有层级结构的数据,如公司组织架构。
- 查找前后记录:比较某个记录与其前后记录的关系,例如,按时间顺序查询订单。
SELECT *
FROM order_items oi
JOIN order_item_notes oin
ON oi.order_id = oin.order_id
AND oi.product_id = oin.product_id
Compound JOIN ON的时候,用AND。主要是确保数据准确性
UNION联合
我们可以合并多段查询的记录
SELECT
order_id,
order_date,
'Active' AS status
FROM orders
WHERE order_date >= '2019-01-01'
UNION
SELECT
order_id,
order_date,
'Archived' AS status
FROM orders
WHERE order_date < '2019-01-01'
SELECT first_name
FROM customers
UNION
SELECT name
FROM shippers
can use in the same table or different table
Practice
SELECT first_name,points,'Bronze' AS type
FROM customers
WHERE points < 2000
UNION
SELECT first_name,points,'Silver' AS type
FROM customers
WHERE points between 2000 and 3000
ORDER BY first_name
输出
| first_name | points | type |
|---|---|---|
| Alice | 1500 | Bronze |
| David | 1800 | Bronze |
| Frank | 1800 | Bronze |
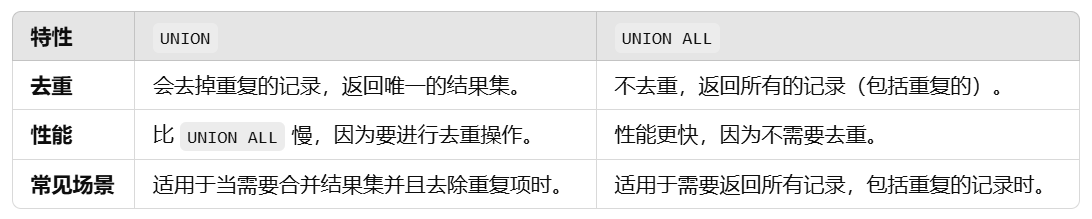
UNION 和 UNION ALL 的区别:
UNION 常用场景:
- 合并不同条件下的查询结果:当你需要从同一个表中获取不同条件下的数据,并且不希望出现重复时,可以使用 UNION。
- 数据清洗:有时从多个来源获取的数据可能有重复,通过 UNION 可以去除这些重复数据。
- 报告和统计:当你需要从多个查询中合并数据,并且只关心不同的记录时,使用 UNION 是理想的选择。
Chapter 5
Aggregate Function
MAX()
MIN()
AVG()
SUM()
COUNT()
Must use ()
Only Operate in NOT NULL values, if you have null value in the column, it will not be included in the function. 返回的非空payment dates的记录数。
如果想得到所有条目,不管是不是空值,用*
COUNT(*) AS total_records
所有示例如下:
SELECT
MAX(invoice_total) AS highest, -- also used in date MAX() the lastest date
MIN(invoice_total) AS lowest,
AVG(invoice_total) AS average,
SUM(invoice_total) AS total,
COUNT(payment_date) AS count_of_payments,
COUNT(DISTINCT client_id) AS total_records
FROM invoices
WHERE invoice_date > '2019-07-01'
同时,我们也可以写表达式
SUM(invoice_total * 1.1) AS total,
程序会先将所有的invoice_total * 1.1,再把所有的Value加起来。
- WHERE 的语句应用在被筛选条件之后的数据
如果有重复的,用DISTINCT Keyword
Practice

SELECT
'First half of 2019' AS date_range,
SUM(invoice_total) AS "total_sales",
SUM(payment_total) AS "total_payment",
(SUM(invoice_total) - SUM(payment_total) ) AS "what_we_expect"
FROM invoices
WHERE invoice_date
Between '2019-01-01' AND '2019-06-30'
UNION
SELECT
'Second half of 2019' AS date_range,
SUM(invoice_total) AS "total_sales",
SUM(payment_total) AS "total_payment",
(SUM(invoice_total) - SUM(payment_total) ) AS "what_we_expect"
FROM invoices
WHERE invoice_date
Between '2019-07-01' AND '2019-12-31'
UNION
SELECT
'Total' AS date_range,
SUM(invoice_total) AS "total_sales",
SUM(payment_total) AS "total_payment",
(SUM(invoice_total) - SUM(payment_total) ) AS "what_we_expect"
FROM invoices
WHERE invoice_date
Between '2019-01-01' AND '2019-12-31'
Group By
We want to know the sum for each client.

SELECT
client_id,
SUM(invoice_total) AS total_sales
FROM invoices i
JOIN clients USING (client_id)
WHERE invoice_date > '2019-07-01'
GROUP BY client_id
ORDER BY total_sales DESC

SELECT
state,
city,
SUM(invoice_total) AS total_sales
FROM invoices i
JOIN clients USING (client_id)
GROUP BY state,city
Practice

SELECT date,pm.name,sum(amount)
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY date,payment_method
ORDER BY date
Having Clauses
SELECT
client_id
SUM(invoice_total) AS total_sales
FROM invoices
WHERE total_sales > 500 -- error
GROUP BY client_id
-----------------------------------
SELECT
client_id
SUM(invoice_total) AS total_sales
FROM invoices
GROUP BY client_id
Having total_sales > 500 -- correct
我们想知道每个客户的total sales大于500的。
因为此时我们还没有group by,所以是不能用where的
- 用WHERE我们可以在分组行之前筛选数据
- Having子句让我们可以在分组行之后筛选数据
SELECT
client_id
SUM(invoice_total) AS total_sales
COUNT(*) AS number_of_invoices
FROM invoices
GROUP BY client_id
Having total_sales > 500 AND number_of_invoices > 5
Having在这里用到的total_sales的列,一定得是我们select子句中已经选中的,不能随意选我们要的column。
Practice

SELECT
c.customer_id,
c.first_name,
c.last_name,
SUM(oi.quantity * oi.unit_price) AS total_sales
FROM customers c
JOIN orders o USING(customer_id)
JOIN order_items oi USING(order_id)
WHERE state = ('VA')
GROUP BY c.customer_id,
c.first_name,
c.last_name
HAVING total_sales > 100
ROLLUP

SELECT
client_id,
SUM(invoice_total) AS total_sales
FROM invoices
GROUP BY client_id WITH ROLLUP
我们得到一行有总sales的row。
Practice

SELECT pm.name AS payment_method,
sum(amount) AS total
FROM payment_methods pm
JOIN payments p
ON p.payment_method = pm.payment_method_id
GROUP BY pm.name WITH ROLLUP
Chapter 6
子查询 | Subqueries

USE sql_inventory;
SELECT *
FROM products
WHERE unit_price > (
SELECT unit_price
FROM products
WHERE product_id = 3
)
先运行的是内语句。
Practice

SELECT * FROM sql_hr.employees;
SELECT first_name, last_name
FROM employees
WHERE salary > (
SELECT avg(salary) FROM employees)
IN运算符 | The IN Operator

SELECT *
FROM products
WHERE product_id NOT IN(
SELECT DISTINCT product_id
FROM order_items
)
Practice

SELECT * FROM clients
WHERE client_id NOT IN (
SELECT DISTINCT client_id FROM invoices)
子查询 vs 连接 | Subqueries vs Joins
对于上述的问题,我们有另一种写法
SELECT *
FROM clients
LEFT JOIN invoices USING (client_id)
WHERE invoice_id IS NULL
什么时候用subqueries和join,我们需根据实际案例判断。代码的可读性是重要的判断标准。
Practice
 USE two methods, pick up the one more readability.
USE two methods, pick up the one more readability.
SELECT customer_id, first_name, last_name
FROM customers
WHERE customer_id IN (
SELECT customer_id
FROM orders
WHERE order_id IN(
SELECT order_id
FROM order_items
WHERE product_id = 3)
)
SELECT DISTINCT c.customer_id, first_name, last_name
FROM order_items oi
JOIN orders o
USING (order_id)
JOIN customers c
USING (customer_id)
WHERE product_id = 3
第二个query的阅读性更强,需要用DISTINCT。但是第一个在数据库较大的情况下占用资源少。
ALL关键字 | The ALL Keyword

-- invoice_total 与一个数字作比较
SELECT *
FROM invoices
WHERE invoice_total > (
SELECT MAX(invoice_total)
FROM invoices
WHERE client_id = 3)
SELECT *
FROM invoices
WHERE invoice_total > ALL(
-- 返回的是list of value
SELECT invoice_total
FROM invoices
WHERE client_id = 3
)
第二个query先执行内语句。得出一个column的invoice_total。
这里的ALL是指满足后面所有的条件。
大于最大值和大于所有值。第一组是直接获取一个单一值(MAX()),效率更高。
ANY关键字 | The ANY Keyword

SELECT *
FROM clients
WHERE client_id IN (
SELECT client_id
FROM invoices
GROUP BY client_id
HAVING COUNT(*) >= 2
)
= ANY () 和 IN是一样的意思

SELECT *
FROM clients
WHERE client_id = ANY (
SELECT client_id
FROM invoices
GROUP BY client_id
HAVING COUNT(*) >= 2
)
*相关子查询 | Correlated Subqueries


首先来到员工表,对每位员工执行这段子查询。
计算同一个部门员工的平均工资(同一个office_id)
如果这名员工的工资高于平均值,这名员工就会被返回在最终结果里。
SELECT *
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM employees
WHERE office_id = e.office_id
)
为什么需要 WHERE office_id = e.office_id?
这句条件的作用是:
对每个员工,计算其所在办公室的平均工资。 office_id = e.office_id 确保子查询只计算当前员工所在办公室的工资平均值,而不是计算所有员工的平均工资。
Practice

SELECT *
FROM invoices i
WHERE invoice_total >
(SELECT AVG(invoice_total)
FROM invoices
WHERE i.client_id = client_id)
*EXISTS运算符 | The EXISTS Operator
 常规方法
常规方法
SELECT *
FROM clients
WHERE client_id IN (
SELECT DISTINCT invoice_id
FROM invoices)
优化方法
SELECT *
FROM clients c
WHERE EXISTS (
SELECT client_id
FROM invoices
WHERE client_id = c.client_id) -- corelated inter query
不用IN。WHERE EXISTS不用像WHERE column IN那样返回一个list,而是直接搜索。适用于大数据量。

Chapter 7
1. Numeric Function 数值函数
SELECT ROUND(5.73,1);
SELECT TRUNCATE (5.732,2);
SELECT CEILING(5.23); -- 上限函数
SELECT FLOOR(5.2);
SELECT ABS(-5.2);
SELECT RAND(); -- random value between 0 and 1
2. String functions 字符串函数
SELECT LENGTH("think");
SELECT UPPER("think");
SELECT LOWER("think");
SELECT LTRIM(" think"); -- left trim 去掉左侧空格
SELECT LTRIM("think "); -- left trim 去掉右侧空格
SELECT TRIM(" think "); -- left trim 去掉前后空格
SELECT LEFT("think",2); -- return left side of the string, th
SELECT RIGHT("think",2); -- return right side of the string, nk
SELECT SUBSTRING('Kingdomwhd', 2,5); -- the 2rd agument is start pos(begin from 1), 3th. is the end position
SELECT LOCATE('n','KINdergarten'); -- 寻找n在后面这个单词的哪个位置,not case sensitive;没有单词返回0
SELECT REPLACE('Kindergarten','garten','garden'); -- 替换
SELECT CONCAT('first','last'); -- 合并
-- utility
SELECT CONCAT(first_name,'',last_name) AS full_name
FROM customers
3. Date functions 日期函数
SELECT
NOW(), -- select current date and time
CURDATE(), -- current date without time
CURTIME(), -- current time
YEAR(NOW()), -- current year
MONTH(NOW()),
DAY(NOW()),
HOUR(NOW()), -- or minute/second
DAYNAME(NOW()), -- or monthname
-- if you want to export the data into other DBMS, use `extract`
EXTRACT(DAY FROM NOW())
Practice
SELECT *
FROM orders
WHERE YEAR(order_date) = YEAR(NOW())
4. Formatting Dates and Time
SELECT DATE_FORMAT(NOW(),'%m %y'); -- 04 22
SELECT DATE_FORMAT(NOW(),'%M %d %Y'); -- April 25 2022
SELECT TIME_FORMAT(NOW(),'%H %i %p') -- 17 21 PM
5. Calculating Dates and Time
SELECT DATE_ADD(NOW(),INTERVAL 1 DAY) -- 明天的日期
SELECT DATE_ADD(NOW(),INTERVAL 1 YRAR) -- 明天的日期
SELECT DATEDIFF('2019-01-05','2019-01-01') -- 4
SELECT TIME_TO_SEC('09:00') -- 32400
SELECT TIME_TO_SEC('09:00') - TIME_TO_SEC('09:02') -- -120
6. IFNULL 和 COALESCE函数
在 SQL 中,IFNULL 和 COALESCE 都是用于处理 NULL 值的函数。它们的主要作用是提供一个替代值来代替 NULL。
IFNULL 和 COALESCE 的介绍 在 SQL 中,IFNULL 和 COALESCE 都是用于处理 NULL 值的函数。它们的主要作用是提供一个替代值来代替 NULL。
- IFNULL函数
功能:当第一个参数是 NULL 时,返回第二个参数的值;否则返回第一个参数的值。 语法:
IFNULL(expression, replacement)
- expression:需要检查是否为 NULL 的表达式。
- replacement:如果 expression 是 NULL 时返回的值。
SELECT IFNULL(NULL, 'Default Value'); -- 结果是 'Default Value'
SELECT IFNULL(100, 'Default Value'); -- 结果是 100
如果shipper是null,return 'not assigned’
use sql_store;
SELECT
order_id,
IFNULL(shipper_id, 'Not assigned') AS shipper
FROM orders
- COALESCE 函数 功能:返回参数列表中第一个非 NULL 的值。如果所有参数都是 NULL,则返回 NULL。
COALESCE(expression1, expression2, ..., expressionN)
- 参数列表按顺序检查,返回第一个非 NULL 的值。
SELECT COALESCE(NULL, NULL, 'Default Value'); -- 结果是 'Default Value'
SELECT COALESCE(NULL, 100, 'Default Value'); -- 结果是 100
SELECT employee_id, COALESCE(salary, bonus, 0) AS income
FROM employees;
逻辑是:
- 如果 salary 非空,返回 salary。
- 如果 salary 是 NULL 且 bonus 非空,返回 bonus。
- 如果两者都为空,返回 0。

如果shipper_id是null,返回comments。如果comments也是null,返回’not assigned’
use sql_store;
SELECT
order_id,
COALESCE(shipper_id,comments, 'Not assigned') AS shipper
FROM orders
Practice

use sql_store;
SELECT
CONCAT(first_name,'',last_name) AS customer,
COALESCE(phone,"Unkonwn") AS phone
FROM customers
7. The IF Function
-- IF(expression,first,second)
SELECT
order_id,
order_date,
IF(YEAR(order_date) = YEAR(NOW()),
'Active', 'Archievd') AS status
FROM orders

SELECT
product_id,
name,
COUNT(*) AS orders,
IF(COUNT(*) > 1, "many times","Once") AS frequency
FROM products
JOIN order_items USING(product_id)
GROUP BY product_id, name
8. The case operator 多条件
SELECT
order_id,
CASE
WHEN YEAR(order_date) = YEAR(NOW()) THEN "Active"
WHEN YEAR(order_date) = YEAR(NOW()) - 1 THEN "Last year"
WHEN YEAR(order_date) < YEAR(NOW()) - 1 THEN "Archieved"
ELSE 'future'
END AS category
FROM orders

